TileDB Global Database for GEDI Data#
Important
If you use the database for your publications, please acknowledge that the dataset has been processed using gediDB:
Besnard, S., Dombrowski, F., & Holcomb, A. gediDB [Computer software]. https://doi.org/10.5281/zenodo.13885229.
Overview#
The publicly available TileDB global database, managed by the Global Land Monitoring group at GFZ-Potsdam, stores all processed GEDI version 2 data with a robust and scalable architecture. All granules for the products L2A, L2B, L4A, and L4C have been ingested into the database. The data is stored in a Ceph object storage managed by the GFZ data center, with a current size of approximately 20TB. It enables efficient spatial, temporal, and attribute-based queries. This page provides an overview of the database setup, configuration, and access methods using the gediDB package.
Ceph Object Storage Configuration#
The TileDB global database utilizes a Ceph object storage backend to efficiently manage and distribute GEDI data. Below are the key characteristics of the Ceph bucket:
Bucket Name:
dog.gedidb.gedi-l2-l4-v002Access Endpoint:
https://s3.gfz-potsdam.deRegion:
eu-central-1Total Storage Used: ~20TB
Access Control: Public
Query Support: Optimized for spatial and temporal queries
For users accessing the database programmatically, interactions with the Ceph bucket are abstracted by the gediDB package, which retrieves data seamlessly from TileDB. Advanced users with direct access to the Ceph storage layer may utilize S3-compatible tools (such as aws s3api or rclone) to interact with the data.
TileDB Database Configuration#
The database configuration defines key parameters for data storage, tiling, and query efficiency. A critical aspect of the database is the application of spatial consolidation, where fragments belonging to the same 10x10-degree spatial windows are consolidated together. This strategy significantly enhances query performance by reducing the number of fragments accessed during spatial queries.
Below is the structure of the configuration file used to build the TileDB database:
# database parameters
tiledb:
storage_type: 's3'
s3_bucket: "dog.gedidb.gedi-l2-l4-v002"
url: "https://s3.gfz-potsdam.de"
overwrite: false
temporal_tiling: "weekly"
chunk_size: 10
time_range:
start_time: "2018-01"
end_time: "2030-12-31"
spatial_range:
lat_min: -56.0
lat_max: 56.0
lon_min: -180.0
lon_max: 180.0
dimensions: ['latitude', 'longitude', 'time']
s3_settings:
connect_timeout_ms: "300000"
request_timeout_ms: "600000"
connect_max_tries: "10"
multipart_part_size: "52428800"
backoff_scale: "2.0"
backoff_max_ms: "120000"
cell_order: "hilbert"
capacity: 100000
The configuration file contains:
Storage Type: Specifies s3 for cloud-based storage.
Time Range: Defines the global temporal coverage.
Spatial Range: Sets the global bounding box for latitude and longitude.
S3 Settings: Configures connection and request parameters for S3.
Note
The current database architecture is somewhat experimental, and different approaches may be more suitable to improve the speed of spatial and temporal queries. Users are encouraged to provide feedback and suggestions for optimizing the tileDB database configuration.
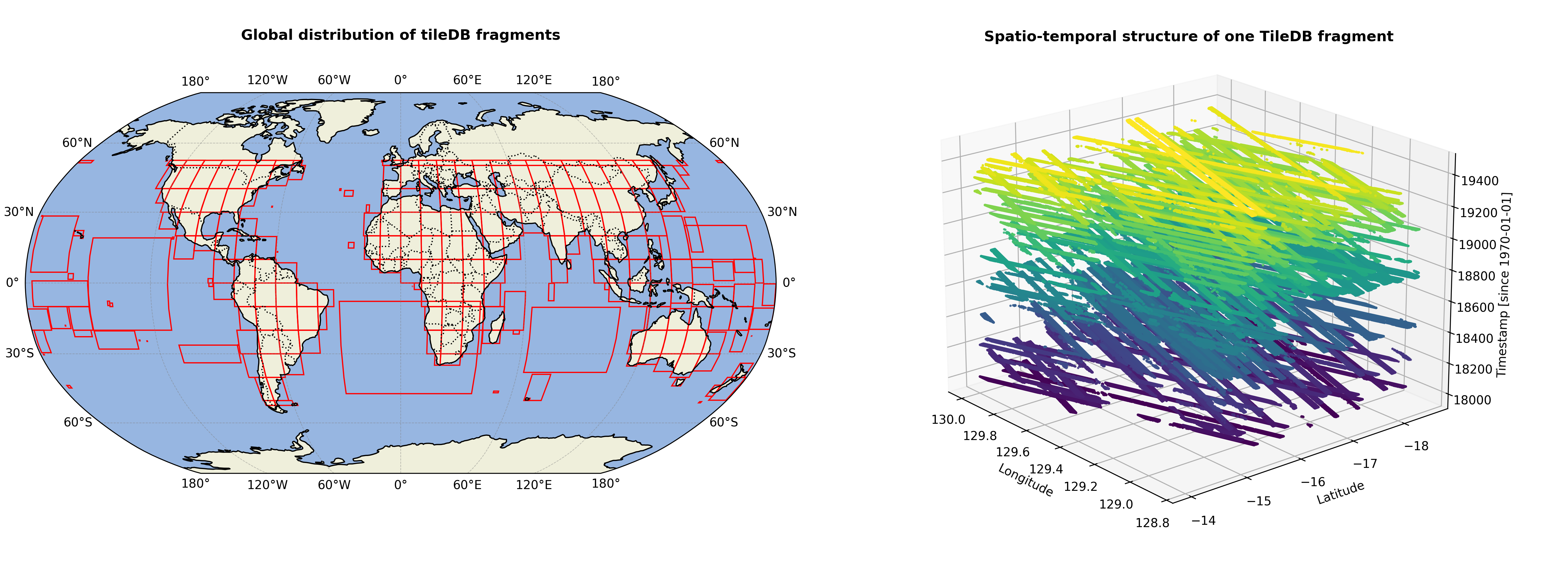
Figure 2: The data structure in the TileDB Global Database for GEDI Data.#
List of the available variables#
The database includes a wide range of variables, covering spatial coordinates, elevation data, vegetation metrics, biomass estimates, and quality flags across multiple GEDI products (L2A, L2B, L4A, L4C). Below is a table of available variables stored in the database:
Variable Name |
Description |
Units |
Product |
|---|---|---|---|
agbd |
Aboveground biomass density |
Mg/ha |
L4A |
agbd_pi_lower |
Lower prediction interval for aboveground biomass density |
Mg/ha |
L4A |
agbd_pi_upper |
Upper prediction interval for aboveground biomass density |
Mg/ha |
L4A |
agbd_se |
Standard error of aboveground biomass density |
Mg/ha |
L4A |
agbd_t |
Model prediction in fit units |
adimensional |
L4A |
agbd_t_se |
Model prediction standard error in fit units |
adimensional |
L4A |
algorithmrun_flag |
The L2B algorithm run flag |
adimensional |
L2B |
beam_name |
Name of the beam |
adimensional |
L2A |
beam_type |
Type of beam used |
adimensional |
L2A |
cover |
Total canopy cover |
Percent |
L2B |
cover_z |
Cumulative canopy cover vertical profile |
Percent |
L2B |
degrade_flag |
Flag indicating degraded state of pointing and/or positioning information |
adimensional |
L2A |
digital_elevation_model |
TanDEM-X elevation at GEDI footprint location |
Meters |
L2A |
digital_elevation_model_srtm |
STRM elevation at GEDI footprint location |
Meters |
L2A |
dz |
Vertical step size of foliage profile |
Meters |
L2B |
elev_highestreturn_a1 |
Elevation of the highest return detected using algorithm 1, relative to reference ellipsoid |
Meters |
L2A |
elev_highestreturn_a2 |
Elevation of the highest return detected using algorithm 2, relative to reference ellipsoid |
Meters |
L2A |
elev_lowestmode |
Elevation of center of lowest mode relative to reference ellipsoid |
Meters |
L2A |
energy_total |
Total energy detected in the waveform |
adimensional |
L2A |
fhd_normal |
Foliage Height Diversity |
adimensional |
L2B |
l2_quality_flag |
Flag identifying the most useful L2 data for biomass predictions |
adimensional |
L4A |
l2a_quality_flag |
L2A quality flag |
adimensional |
L2B |
l2b_quality_flag |
L2B quality flag |
adimensional |
L2B |
l4_quality_flag |
Flag simplifying selection of most useful biomass predictions |
adimensional |
L4A |
landsat_treecover |
Tree cover in the year 2010, defined as canopy closure for all vegetation taller than 5 m in height as a percentage per output grid cell |
Percent |
L2A |
landsat_water_persistence |
Percent UMD GLAD Landsat observations with classified surface water |
Percent |
L2A |
leaf_off_doy |
GEDI 1 km EASE 2.0 grid leaf-off start day-of-year |
adimensional |
L2A |
leaf_off_flag |
GEDI 1 km EASE 2.0 grid flag |
adimensional |
L2A |
leaf_on_cycle |
Flag that indicates the vegetation growing cycle for leaf-on observations |
adimensional |
L2A |
leaf_on_doy |
GEDI 1 km EASE 2.0 grid leaf-on start day-of-year |
adimensional |
L2A |
modis_nonvegetated |
Percent non-vegetated from MODIS MOD44B V6 data |
Percent |
L2A |
modis_nonvegetated_sd |
Percent non-vegetated standard deviation from MODIS MOD44B V6 data |
Percent |
L2A |
modis_treecover |
Percent tree cover from MODIS MOD44B V6 data |
Percent |
L2A |
modis_treecover_sd |
Percent tree cover standard deviation from MODIS MOD44B V6 data |
Percent |
L2A |
num_detectedmodes |
Number of detected modes in rxwaveform |
adimensional |
L2A |
omega |
Foliage Clumping Index |
adimensional |
L2B |
pai |
Total Plant Area Index |
m²/m² |
L2B |
pai_z |
Plant Area Index profile |
m²/m² |
L2B |
pavd_z |
Plant Area Volume Density profile |
m²/m³ |
L2B |
pft_class |
GEDI 1 km EASE 2.0 grid Plant Functional Type (PFT) |
adimensional |
L2A |
pgap_theta |
Total Gap Probability (theta) |
adimensional |
L2B |
pgap_theta_error |
Total Pgap (theta) error |
adimensional |
L2B |
predict_stratum |
Prediction stratum name for the 1 km cell |
adimensional |
L4A |
predictor_limit_flag |
Prediction stratum identifier (0=in bounds, 1=lower bound, 2=upper bound) |
adimensional |
L4A |
quality_flag |
Flag simplifying selection of most useful data |
adimensional |
L2A |
region_class |
GEDI 1 km EASE 2.0 grid world continental regions |
adimensional |
L2A |
response_limit_flag |
Prediction value outside bounds of training data (0=in bounds, 1=lower bound, 2=upper bound) |
adimensional |
L4A |
rg |
Integral of the ground component in the RX waveform |
adimensional |
L2B |
rh |
Relative height metrics at 1% interval |
Meters |
L2A |
rh100 |
Height above ground of the received waveform signal start |
cm |
L2B |
rhog |
Volumetric scattering coefficient (rho) of the ground |
adimensional |
L2B |
rhog_error |
Rho (ground) error |
adimensional |
L2B |
rhov |
Volumetric scattering coefficient (rho) of the canopy |
adimensional |
L2B |
rhov_error |
Rho (canopy) error |
adimensional |
L2B |
rossg |
Ross-G function |
adimensional |
L2B |
rv |
Integral of the vegetation component in the RX waveform |
adimensional |
L2B |
rx_algrunflag |
Flag indicating signal was detected and algorithm ran successfully |
adimensional |
L2A |
rx_maxamp |
Maximum amplitude of rxwaveform relative to mean noise level |
adimensional |
L2A |
rx_range_highestreturn |
Range to signal start |
Meters |
L2B |
sd_corrected |
Noise standard deviation, corrected for odd/even digitizer bin errors based on pre-launch calibrations |
adimensional |
L2A |
selected_algorithm |
Identifier of algorithm selected as identifying the lowest non-noise mode |
adimensional |
L2A |
selected_l2a_algorithm |
Selected L2A algorithm setting |
adimensional |
L2B |
selected_rg_algorithm |
Selected R (ground) algorithm |
adimensional |
L2B |
sensitivity |
Maxmimum canopy cover that can be penetrated |
adimensional |
L2A |
sensitivity_a1 |
Geolocation sensitivity factor A1 |
adimensional |
L2A |
sensitivity_a2 |
Geolocation sensitivity factor A2 |
adimensional |
L2A |
shot_number |
Unique identifier for each shot |
adimensional |
L4C |
solar_azimuth |
Solar azimuth angle at the time of the shot |
Degrees |
L2A |
solar_elevation |
Solar elevation angle at the time of the shot |
Degrees |
L2A |
stale_return_flag |
Flag indicating return signal above detection threshold was not detected |
adimensional |
L2B |
surface_flag |
Identifier of algorithm selected as identifying the lowest non-noise mode |
adimensional |
L2A |
toploc |
Sample number of highest detected return |
adimensional |
L2A |
urban_proportion |
The percentage proportion of land area within a focal area surrounding each shot that is urban land cover. |
Percent |
L2A |
wsci |
Waveform Structural Complexity Index |
adimensional |
L4C |
wsci_pi_lower |
Waveform Structural Complexity Index lower prediction interval |
adimensional |
L4C |
wsci_pi_upper |
Waveform Structural Complexity Index upper prediction interval |
adimensional |
L4C |
wsci_quality_flag |
Waveform Structural Complexity Index quality flag |
adimensional |
L4C |
wsci_xy |
Horizontal Structural Complexity |
adimensional |
L4C |
wsci_xy_pi_lower |
Horizontal Structural Complexity lower prediction interval |
adimensional |
L4C |
wsci_xy_pi_upper |
Horizontal Structural Complexity upper prediction interval |
adimensional |
L4C |
wsci_z |
Vertical Structural Complexity |
adimensional |
L4C |
wsci_z_pi_lower |
Vertical Structural Complexity lower prediction interval |
adimensional |
L4C |
wsci_z_pi_upper |
Vertical Structural Complexity upper prediction interval |
adimensional |
L4C |
zcross |
Sample number of center of lowest mode above noise level |
Nanoseconds |
L2A |
Accessing the database#
The gediDB Python package simplifies access to the TileDB global database. Below is an example workflow for querying data.
Example Code:
import geopandas as gpd
import gedidb as gdb
# Instantiate the GEDIProvider
provider = gdb.GEDIProvider(
storage_type='s3',
s3_bucket="dog.gedidb.gedi-l2-l4-v002",
url="https://s3.gfz-potsdam.de"
)
# Load region of interest (ROI)
region_of_interest = gpd.read_file('path/to/test.geojson')
# Define variables to query and quality filters
vars_selected = ["agbd", 'rh']
# Query data
gedi_data = provider.get_data(
variables=vars_selected,
query_type="bounding_box",
geometry=region_of_interest,
start_time="2018-01-01",
end_time="2024-07-25",
return_type='xarray'
)
Explanation:
GEDIProvider: Initializes the provider with S3 storage details.
Region of Interest: Defines the geographic area for the query using a GeoJSON file.
Variables: Specifies the variables to extract (e.g., agbd, rh).
Examples and use cases#
Here are some example use cases:
Retrieve Aboveground Biomass Density (AGBD) for a region:
gedi_data = provider.get_data( variables=["agbd"], query_type="bounding_box", geometry=region_of_interest, start_time="2018-01-01", end_time="2024-07-25", return_type='xarray')
Analyze Relative Heights (RH) with additional quality filters:
gedi_data = provider.get_data( variables=["rh"], query_type="bounding_box", geometry=region_of_interest, start_time="2018-01-01", end_time="2024-07-25", quality_filters = { 'sensitivity': '>= 0.9 and <= 1.0', 'beam_type': "== 'full'" }, return_type='xarray')