Overview: Why gediDB?#
GediDB is a scalable Python package built to simplify working with GEDI (Global Ecosystem Dynamics Investigation) data. It offers intuitive modules for processing, querying, and analyzing GEDI data stored in tileDB databases.
The motivation behind gediDB#
Working with GEDI data in its raw HDF5 format can be challenging due to:
Complex data structure: GEDI files are organized by orbit, making it inefficient for users interested in specific regions.
High redundancy: Users often need only a few metrics from across different products for each footprint, yet each HDF5 file contains extensive redundant information, leading to excessive disk and network load.
Filter challenges: When working with raw GEDI HDF5 files, researchers encounter a large volume of data, including many low-quality shots that are not suitable for scientific analysis. Although the raw HDF5 files contain various quality-related flags and variables, these filters are not pre-applied.
GediDB was designed to address these issues by providing an efficient, pre-filtered tileDB database system that combines GEDI L2A+B and L4A+C products.
What gediDB enables#
By overcoming GEDI’s high dimensionality and spatial complexities, gediDB offers powerful capabilities that simplify data access and analysis, including:
Efficient, region-specific querying: Quickly filter data by regions, variables, and time intervals for targeted analysis.
Advanced geospatial querying: Harness tileDB for spatially enabled data retrieval within specified boundaries.
Distributed processing: Leverage parallel engines to parallelize and scale data processing, ensuring large-scale GEDI datasets are handled efficiently.
Unified GEDI products: Easily combine data from multiple GEDI levels (i.e., Levels 2A, 2B, 4A and 4C) into a single dataset, enabling more comprehensive analysis.
By abstracting the complexity of raw GEDI HDF5 files, gediDB helps researchers to focus on their scientific objectives without data management bottlenecks.
What does processing mean in gediDB?#
Processing within gediDB involves the following steps:
Data Transformation: Conversion of raw HDF5 granules into TileDB arrays for efficient storage and querying.
Spatial and Temporal Restructuring: Reorganizing the data from orbit-based granules into a spatially and temporally indexed format to facilitate region-specific and time-based analyses.
Filtering: Applying user-defined filters, such as quality flags or exclusion criteria, to reduce data size and focus on relevant observations.
Metadata Enhancement: Adding metadata that improves dataset usability, such as variable descriptions and dataset provenance information.
It is important to note that gediDB maintains the scientific integrity of the original GEDI measurements. No temporal aggregation, spatial binning, or correction factors are applied unless explicitly requested by the user.
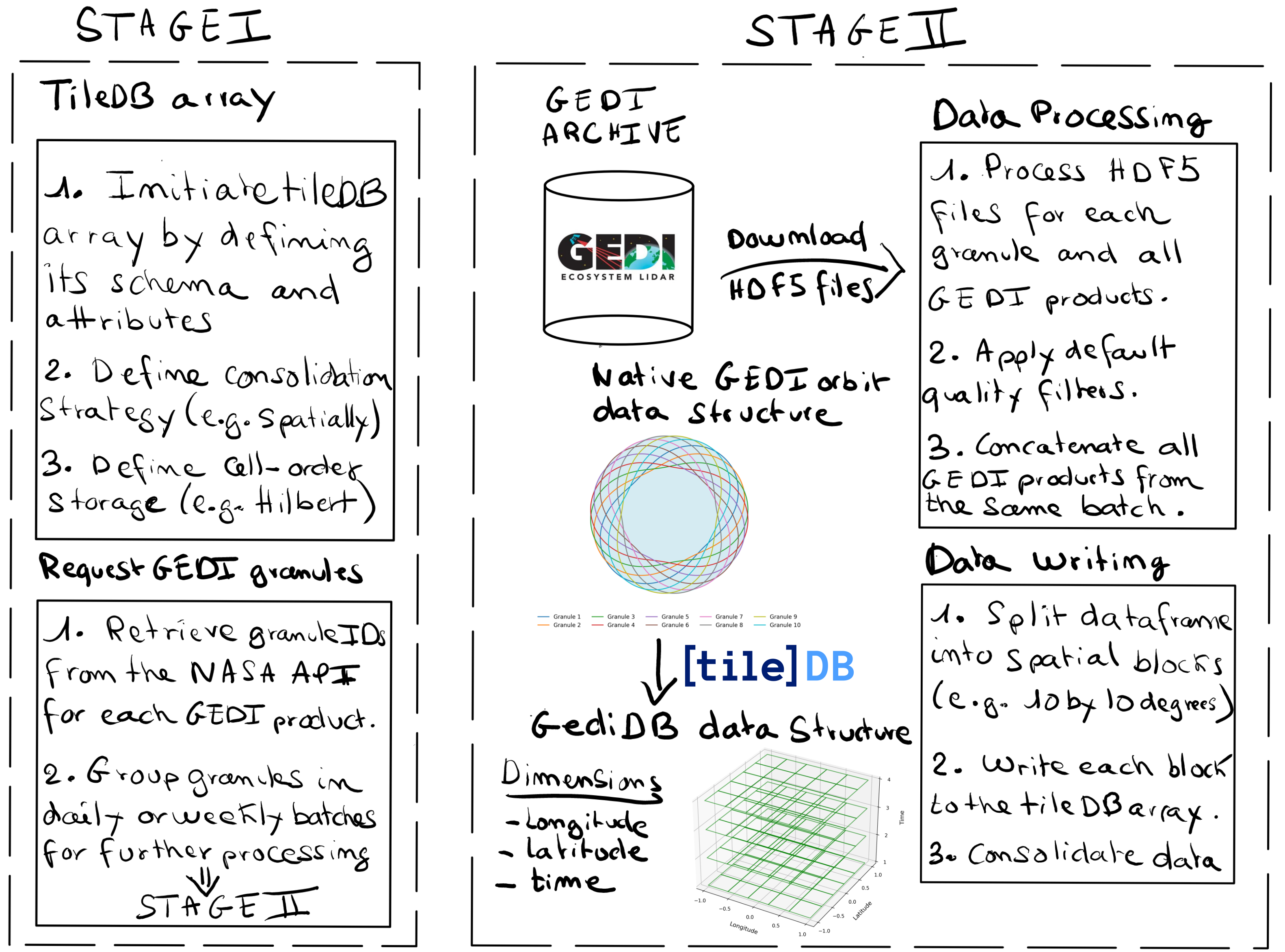
Figure 1: A schematic representation of the gediDB data workflow.#
GEDI data structure and gediDB’s solution#
GEDI’s multi-dimensional data—spanning time, space, and height—presents unique challenges in processing and interpretation. GediDB simplifies these complexities by aligning data dimensions and providing intuitive modules for accessing and manipulating data. Users can:
Filter GEDI data by time and space: Retrieve data within specified geographic or temporal ranges.
Merge and unify GEDI products: Integrate multiple GEDI products for smooth, consolidated analyses.
Perform spatial operations: Execute custom spatial queries based on user-defined boundaries.
Core components of gediDB#
GediDB’s two primary modules facilitate data processing and access:
gedidb.GEDIProcessor: This component manages data processing tasks, ensuring efficient handling and integrity across large GEDI datasets. It includes features for: - Transforming orbit-based HDF5 data into spatially and temporally indexed TileDB arrays. - Filtering and validating data during processing.gedidb.GEDIProvider: The high-level module for querying GEDI data stored in tileDB arrays. It retrieves data as Pandas DataFrames or xarray Datasets, enabling users to specify variables, apply spatial filters, and set time ranges.
These modules provide structured access to GEDI data, preserving relationships and metadata between datasets for comprehensive analysis.
Goals and aspirations#
GediDB’s primary objective is to create an efficient, scalable platform that meets the needs of various research fields, including:
Geosciences: Facilitating research on forest structure, canopy height, and biomass.
Remote Sensing: Enabling cross-referencing GEDI data with other remote sensing products for ecosystem studies.
Data Science & Machine Learning: Supporting developers in integrating GEDI data into data pipelines for modeling and large-scale analyses.
With a robust foundation for querying and processing GEDI data, gediDB aims to be a useful tool for conducting analyses of ecosystem dynamics as inferred from GEDI observations.
—
A collaborative project#
GediDB began as a research tool during Amelia Holcomb’s PhD at the University of Cambridge and evolved into a Python package through collaboration with Simon Besnard and Felix Dombrowski from the Global Land Monitoring Group at the Helmholtz Center Potsdam GFZ German Research Centre for Geosciences. This transition to a production-ready tool was driven by the need to handle large datasets and complex queries effectively. The project remains open-source and welcomes contributions from the research community to support its growth and adaptability.
—